

chapter1 : 트랜스포머 소개
트랜스포머(transformer) 맛보기
Attention is All You Need(2017)에서 시퀀스 모델링을 위한 새로운 신경망 아키텍처를 제안함
순환신경망(RNN) 대비 기계 번역 학습의 품질과 훈련 비용 좋음
효율적인 전이학습 방법(ULMFiT)으로 매우 크고 다양한 말뭉치(corpus)에서 장단기메모리(LSTM) 신경망을 훈련해 적은 양의 레이블링된 데이터로도 높은 성능
가장 유명한 트랜스포머 모델
1) GPT(Generative Pretrained Transformer)
2) BERT(Bidirectional Encoder Representations from Transformers)다양한 트랜스포머 모델 time line
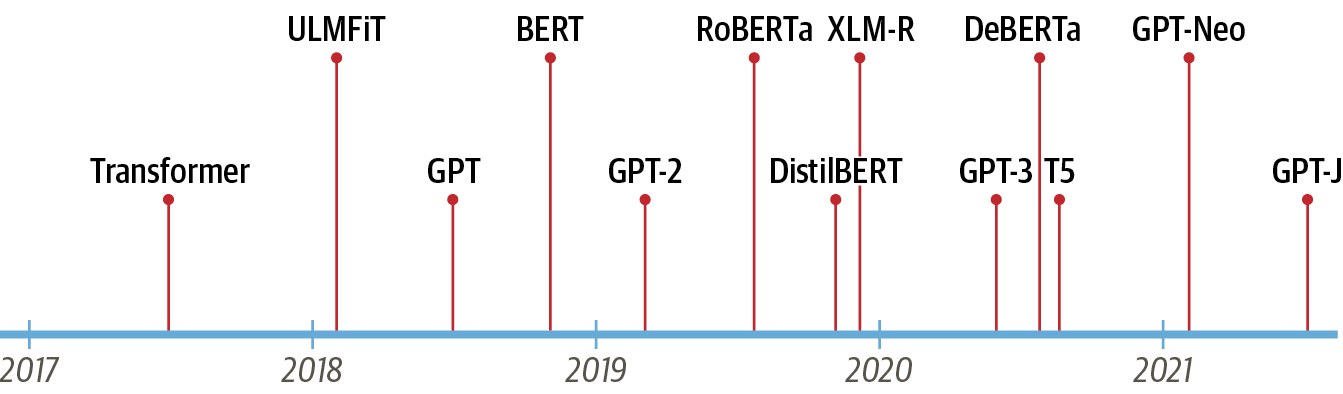
[참조] LLM time line

트랜스포머의 기초가 되는 핵심 개념
1. 인코더-디코더 프레임 워크
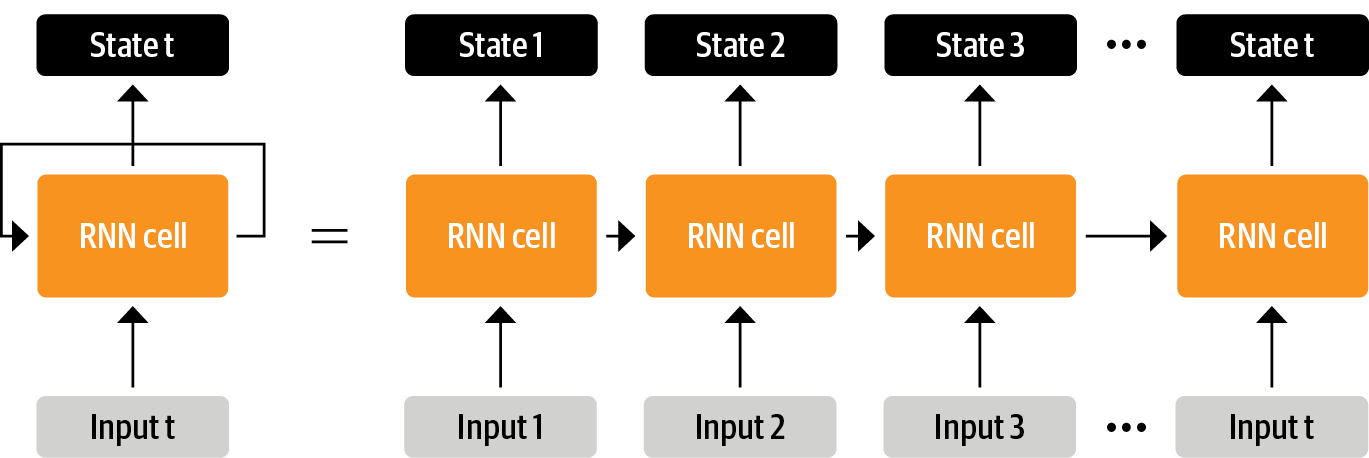
1) RNN : 입력 받은 데이터를 네트워크에 통과시키고 hidden state라고 불리는 벡터를 출력함과 동시에 모델은 피드백 루프를 통해 일부 정보를 다시 자신에게 전달여 다음 단계에서 해당 정보를 사용하는 순환 신경망
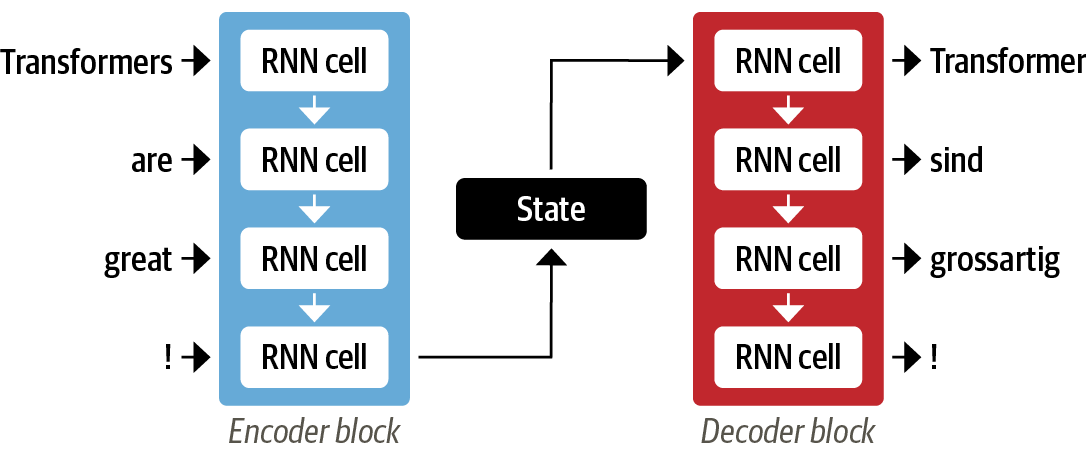
2) Sequence-to-Sequence : 입력과 출력의 데이터 길이가 다른 데이터 분석에 용이하며, 인코더는 입력 시퀀스의 정보를 숫자로 표현하고, 마지막에 hidden state에 정보를 답고 디코더에 전달하여 출력 시퀀스를 생성함.
- hidden state의 정보 병목 현상 발생 주의 : 긴 시퀀스의 경우, 시작 부분의 정보가 하나의 고정된 표현으로 압축되는 과정에서 손실 가능
2. 어텐션 메커니즘
1) attention
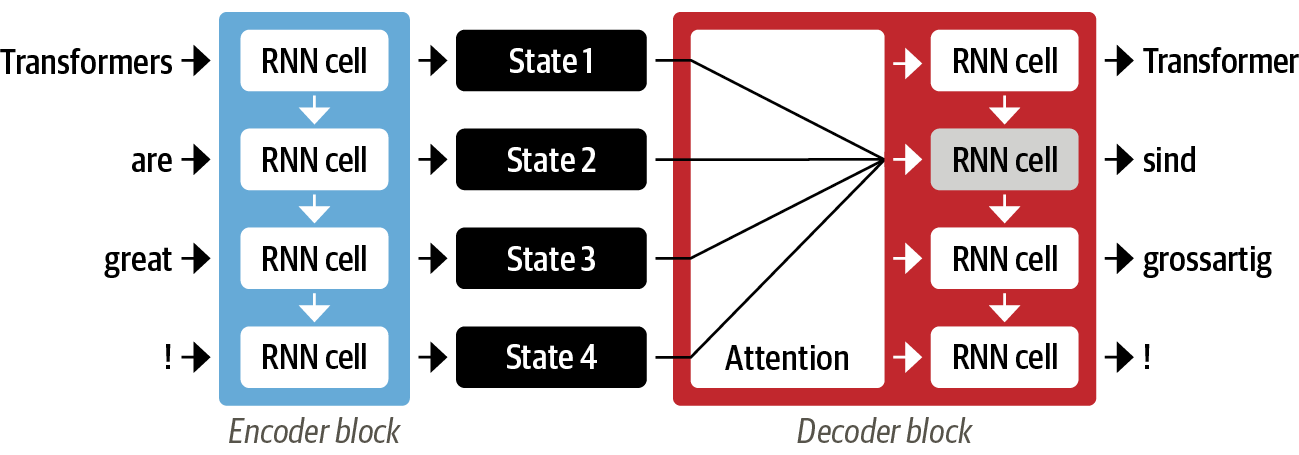
- 인코더가 입력 시퀀스마다 하나의 hidden state를 생성하는 대신, 인코더는 각 단계마다 hidden state를 출력하고 디코더가 해당 hidden state에 접근할 수 있도록 함
- 디코더에서 우선적으로 사용할 hidden state를 결정하는 메카니즘이 필요함
- attention은 디코더가 각 디코딩 타임스텝마다 인코더 상태에 대해 다른 가중치, 즉 "주의"를 할당
** 즉, attention 메커니즘은 디코더가 출력 시퀀스의 각 위치마다 어떤 입력 상태를 주로 주의해야 할지 결정**
- 예를 들면, 기계번역에서 두 문장을 토큰화하여 각 단어별로 attention 가중치를 보면, 다른 순서임에도 불구하고 'zone' & 'area', 'europeenne' & 'European'이 가중치가 높은 것을 볼 수 있음

- 한계 : 입력 시퀀스에 대한 병렬처리가 안됨
=> 순환을 완전히 배제하고 self-attention으로 해결
2) self-attention
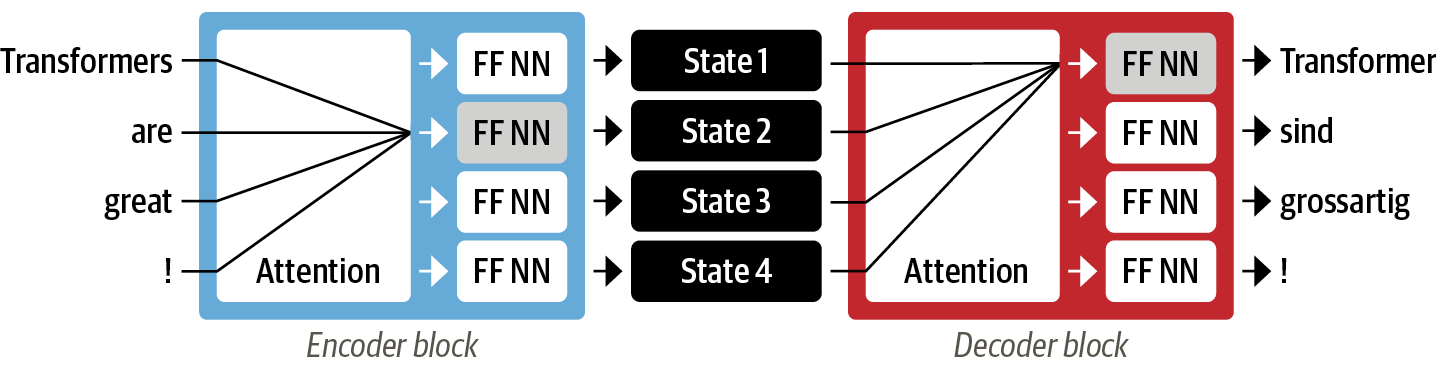
- 인코더와 디코더가 모두 self-attention mechanism으로 구성됨
3. 전이 학습
1) 기본 개념
기본에 학습된 모델을 다른 새로운 작업에 적용하거나 세밀하게 조정함
- 전이학습의 아키텍쳐는 Body와 Head로 이뤄짐
- 기존의 body를 유지하면서 특정 작업을 위해 새로운 head를 추가하거나 수정
- Body : 사전 학습된 모델의 기본 부분으로 큰 데이터셋에서 이미 학습된 일반적인 특징들을 포착
예) 컴퓨터 비전 : 이미지의 각 픽셀에 대한 특징, 가장자리, 색상 등을 포함하여 이미지 분류, 객체 감지 등과 같은 다양한 컴퓨터 비전 작업에 유용한 기본적인 특징을 추출하는 데 사용됨 - Head : 특정 작업에 맞게 모델의 상단 부분을 수정하는 역할로 작업에 맞게 적절한 출력을 생성하도록 설계됨
예) 컴퓨터 비전 : 이미지 분류 작업을 위한 클래스를 분류, 객체 감지 작업을 위한 객체의 경계 상자와 클래스를 예측하는 데 사용됨
- Body : 사전 학습된 모델의 기본 부분으로 큰 데이터셋에서 이미 학습된 일반적인 특징들을 포착
2) ULMFiT - NLP 전이학습 예시
사전 학습된 LSTM 모델을 다양한 작업에 적용하기 위한 프레임워크 개발 연구 프로젝트 결과
- ULMFiT 주요 3단계

- 1단계 사전 학습 (Pretraining): 다음 단어를 맞추는 언어모델링
- 2단계 도메인 적응 (Domain adaptation): 도메인 내 말뭉치에 적응시켜 말뭉치에서 다음 단어 예측
- 3단계 미세 조정 (Fine-tuning): 분류 레이어를 추가하여 언어 모델 파인 튜닝
트랜스포머 주요 모델 소개
1) GPT (Generative Pre-trained Transformer)
- Transformer 아키텍처의 디코더 부분 사용
- ULMFiT와 동일한 언어 모델링 접근 방식을 사용
- BookCorpus라는 데이터셋에서 사전 학습(어드벤처, 판타지, 로맨스 등 다양한 장르의 7,000권)
2) BERT (Bidirectional Encoder Representations from Transformers)
- Transformer 아키텍처의 인코더 부분 사용
- 마스크된 언어 모델링을 사용
- BookCorpus와 영어 위키피디아에서 사전 학습
트랜스포머의 주요 도전 과제
- 언어 : 주로 영어를 학습하여 영어 외의 언어에 대한 모델 부족
1) 다중 언어 트랜스포머
2) 제로샷 교차 언어 전이 - 데이터 가용성 : 레이블링된 데이터가 없거나 소량인 상태에서 효율적인 전이학습 필요
- 긴 문서 처리 : 셀프 어텐션은 문단 정도의 텍스트 길이에서 성능이 좋으며, 문서 처리시 비용 증대
- 불투명성 : 블랙박스 모델
- 편향 : 데이터에 있는 편향이 모델에 전이됨
허깅페이스 트랜스포머와 애플리케이션
- 허깅페이스에서 다양한 트랜스포머 모델에 표준화된 인터페이스를 제공함
- 허깅페이스 생태계 : NLP, ComputerVision 등의 Task를 해결하는 속도를 높이는 다양한 라이브러리와 도구 제공
1) 라이브러리 : 토크나이저, 트랜스포머스, 데이터셋, 액셀러레이트 제공
1-1) 허깅페이스 토크나이저 : 로스트 백엔드로 빠른 텍스트 토큰화 가능, 모델 출력을 적절한 포맷으로 변환하는 전처리, 사후처리 단계 처리 등
1-2) 데이터셋 : 수천개의 데이터셋 제공, 메모리 매핑이라는 특별한 메커니즘을 활용해 램 부족 회피
1-3) 엑셀러레이트 : 훈련 루프를 미세하게 제어할 때 필요, 훈련에 필요한 인프라 전환을 단순화해 워크플로우를 가속화 함
2) 허깅페이스허브 : 사정 훈련된 모델 가중치, 데이터셋, 평가 지표를 위한 스크립트, 문서(모델 카드, 데이터셋 카드) 등- [추가] NLP Tasks, languages, libraries 등의 기준으로 model을 찾아서 사용할 수 있음
[주의] 예제 코드에는 없지만, 현재 구제적인 모델명 등을 넣어서 분석하는 것이 권장됨
import pandas as pd
text = """Dear Amazon, last week I ordered an Optimus Prime action figure \
from your online store in Germany. Unfortunately, when I opened the package, \
I discovered to my horror that I had been sent an action figure of Megatron \
instead! As a lifelong enemy of the Decepticons, I hope you can understand my \
dilemma. To resolve the issue, I demand an exchange of Megatron for the \
Optimus Prime figure I ordered. Enclosed are copies of my records concerning \
this purchase. I expect to hear from you soon. Sincerely, Bumblebee."""1. 텍스트 분류
from transformers import pipeline
classifier = pipeline("text-classification")
outputs = classifier(text)
pd.DataFrame(outputs) 
2. 개체명 인식(NER, Named Entity Recognition)
ner_tagger = pipeline("ner", aggregation_strategy="simple")
outputs = ner_tagger(text)
pd.DataFrame(outputs) 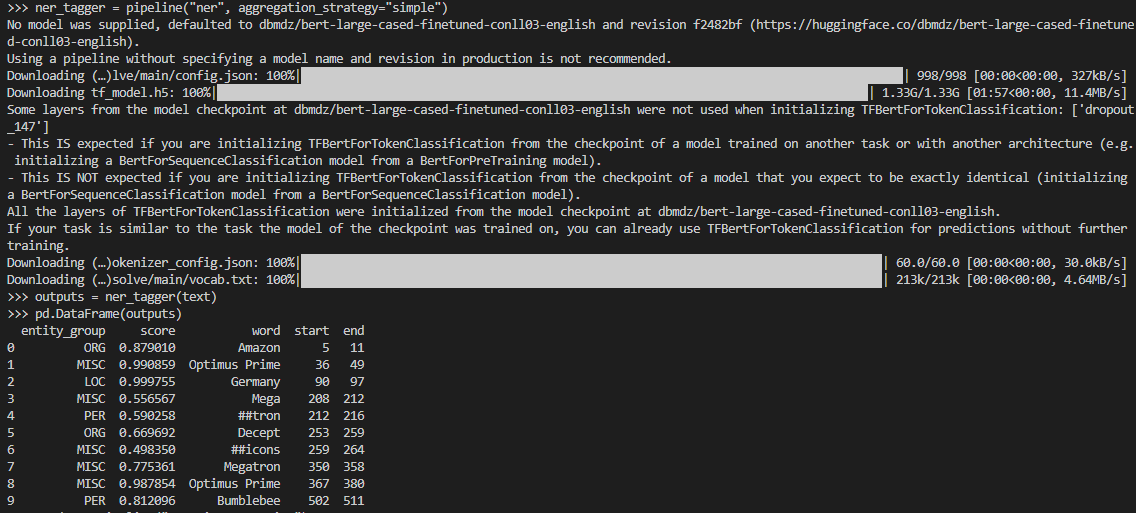
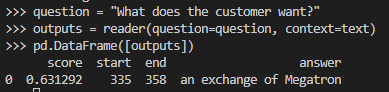
3. 질문답변
reader = pipeline("question-answering")
question = "What does the customer want?"
outputs = reader(question=question, context=text)
pd.DataFrame([outputs]) 
4. 요약
summarizer = pipeline("summarization")
outputs = summarizer(text, max_length=45, clean_up_tokenization_spaces=True)
print(outputs[0]['summary_text'])
5. 번역
translator = pipeline("translation_en_to_de",
model="Helsinki-NLP/opus-mt-en-de")
outputs = translator(text, clean_up_tokenization_spaces=True, min_length=100)
print(outputs[0]['translation_text'])6. 텍스트 생성
#hide
from transformers import set_seed
set_seed(42) # Set the seed to get reproducible results
generator = pipeline("text-generation")
response = "Dear Bumblebee, I am sorry to hear that your order was mixed up."
prompt = text + "\n\nCustomer service response:\n" + response
outputs = generator(prompt, max_length=200)
print(outputs[0]['generated_text'])
'자연어처리' 카테고리의 다른 글
| 트랜스포머 이론 정리 (0) | 2022.10.26 |
|---|---|
| 트랜스퍼 러닝 (0) | 2022.10.05 |
| 토큰화란? (0) | 2022.10.05 |
| 윈도우 python3.X mecab 설치 간단~ (28) | 2021.06.30 |
| [자연어처리] 독학을 위한 자료 모음 (0) | 2019.08.09 |

