
시퀀스-투-시퀀스란?
특정 속성을 지닌 시퀀스를 다른 속성의 시퀀스로 변환하는 작업
주의점 : 소스와 타깃의 길이가 달라도 해당 과제를 수행하는데 문제가 없어야 함
인코더와 디코더
인코더(encoder) : 소스 시퀀스 압축
디코더(decoder) : 타깃 시퀀스 생성
트랜스포머란?
기계 번역 등 시퀀스-투-시퀀스 과제를 수행하는 모델(2017년 구글이 제안)
BERT나 GPT는 프랜스포머 기반 언어 모델임
트랜스포머는 인코더와 디코더 입력이 주어졌을 때 정답에 해당하는 단어(벡터)의 확률값(벡터의 특징, 요솟값, 전체합은 1)을 높이는 방식으로 학습한다.
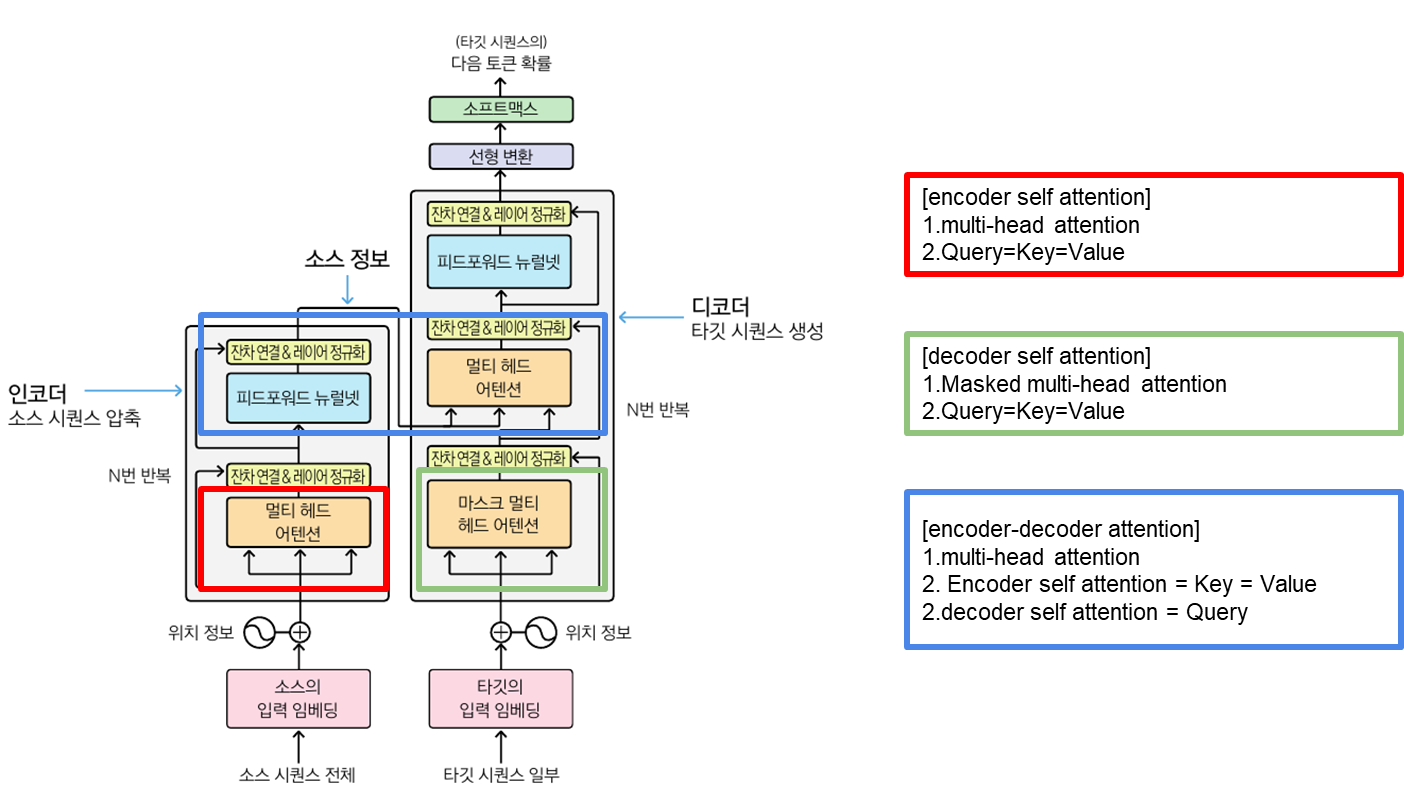
트랜스포머 블록의 요소
1. 트랜스포머 블록
1-1. 멀티 헤드 어텐션(multi-head attendtion) = 셀프 어텐션
1-1-1. 어텐션(attendtion) : 시퀀스 입력에 수행하는 기계학습 방법의 일종으로 중요한 요소에 더 집중해 성능을 끌어 올리는 기법임
1-1-2. 셀프 어텐션(self attendtion) :
1) 합성곱 신경망 (VS 셀프 어텐션)
=> 합성곱 신경망은 합성곱 필터의 크기를 넘는 문맥은 읽어낼 수 없음
2) 순환 신경망 (VS 셀프 어텐션)
=> 시퀀스가 길어질수록 마지막 데이터에 초점을 보내거나 특정 데이터에 정보를 과도하게 반영하여 전체 정보를 왜곡하는 경우가 자주 발생함

3) 어텐션 (VS 셀프 어텐션)
=> 어텐션은 디코더 쪽 RNN이 타깃 시퀀스를 생성할 때, 소스(인코더) 시퀀스 전체에서 어떤 요소를 주목해야 할지 학습시킴

4) 셀프 어텐션
=> 자기 자신에 수행하는 어텐션
=> 셀프 어텐션은 쿼리, 키, 밸류가 서로 영향을 주고받으면서 문장의 의미를 계산함


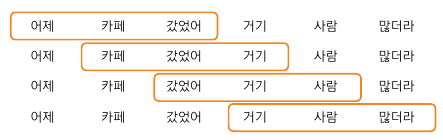
=> 셀프 어텐션 과정
* 1단계 : 쿼리:카페 , 키:[어제, 갔었어, 거기, 사람, 많더라] , 밸류:[01,0.1, 0.2, 0.4, 0.1, 0.1]
* 2단계 : 각 쿼리에 대해 키에 대한 밸류값 계산
* 3단계 : 밸류들의 가중합 계산
(가중의 합 : 복수의 수에 대해 특정 가중치를 곱한 후 이 곱샘의 결과들을 합함)
* 4단계: 소프트맥스로 확률값 계산
5) 멀티 헤드 어텐션 : 셀프 어텐션을 동시에(독자적으로) 여러 번 수행하는 것
1-2. 피드포워드 뉴럴 네트워크(feedforward neural network)
=> 입력층(x), 은닉층(h), 출력층(y) 3개 계층으로 구성됨 / 트랜스포머의 피드포워드 활성 함수는 ReLu임
1-3. 전차 연결(residual connection)
1-4. 레이어 정규화(layer normalization)
1-5. 마스크를 적용한 멀티 헤드 어텐션(masked multi-head attendtion)
트랜스포머 인코더 블록
트랜스포머 디코더 블록
== 참고 ==
Do it! BERT와 GPT로 배우는 자연어 처리 : 트랜스포머 핵심 원리와 허깅페이스 패키지 활용법
'자연어처리' 카테고리의 다른 글
| [도서 스터디] 트랜스포머를 활용한 자연어 처리_chapter1 : 트랜스포머 소개 (0) | 2023.08.04 |
|---|---|
| 트랜스퍼 러닝 (0) | 2022.10.05 |
| 토큰화란? (0) | 2022.10.05 |
| 윈도우 python3.X mecab 설치 간단~ (28) | 2021.06.30 |
| [자연어처리] 독학을 위한 자료 모음 (0) | 2019.08.09 |
